Abstract
Collective Motion Generation is essential in entertainment industries such as animation and games as well as in strategic fields like urban simulation and planning. This new task requires an intricate integration of control and generation to realistically synthesize crowd dynamics under specific spatial and semantic constraints, whose challenges are yet to be fully explored. On the one hand, existing human motion generation models typically focus on individual behaviors, neglecting the complexities of collective behaviors. On the other hand, recent methods for multi-person motion generation depend heavily on pre-defined scenarios and are limited to a fixed, small number of inter-person interactions, thus hampering their practicality. To overcome these challenges, we introduce CrowdMoGen, a zero-shot text-driven framework that harnesses the power of Large Language Model (LLM) to incorporate the collective intelligence into the motion generation framework as guidance, thereby enabling generalizable planning and generation of crowd motions without paired training data.
Pipeline
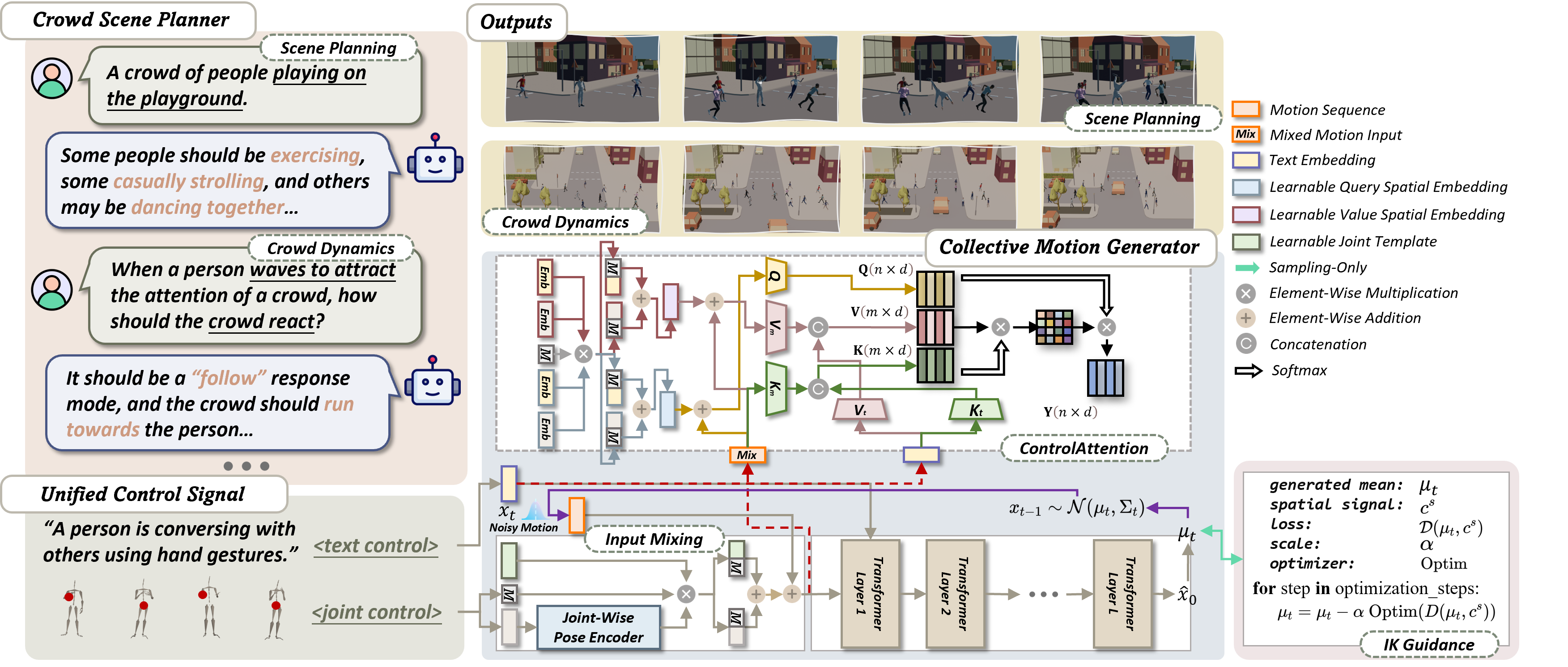
Figure 1. Overview of the proposed CrowdMoGen.
CrowdMoGen is a novel two-stage, zero-shot framework for Crowd Motion Generation, which separates motion decision-making from motion generation into two distinct tasks.
1) Crowd Scene Planner uses a Large Language Model (LLM) to interpret and decide on crowd movements based on user scenarios, giving our method zero-shot capabilities.
It provides detailed semantic attributes (like action categories) and spatial attributes (like trajectories and interactions) for each individual, managing both overall crowd dynamics and individual interactions.
2) Collective Motion Generator enhances the realism of generated motions and ensures strict adherence to control signals through joint-wise InputMixing, customized ControlAttention mechanisms, and carefully designed training objectives.
Gallery
Demo Video
Fantastic Human Generation Works 🔥
Motion Generation
⇨ LMM: Large Motion Model for Unified Multi-Modal Motion Generation
⇨ FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing
⇨ InsActor: Instruction-driven Physics-based Characters
⇨ ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
⇨ DiffMimic: Efficient Motion Mimicking with Differentiable Physics
⇨ MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
⇨ Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
2D Human Generation
⇨ Text2Performer: Text-Driven Human Video Generation
⇨ Text2Human: Text-Driven Controllable Human Image Generation
⇨ StyleGAN-Human: A Data-Centric Odyssey of Human Generation
3D Human Generation
⇨ EVA3D: Compositional 3D Human Generation from 2D Image Collections
⇨ AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
Acknowledgement
This work is supported by NTU NAP, MOE AcRF Tier 2 (T2EP20221-0033), and under the RIE2020 Industry Alignment Fund - Industry Collaboration Projects (IAF-ICP) Funding Initiative, as well as cash and in-kind contribution from the industry partner(s).
We referred to the project page of Nerfies when creating this project page.